浏览器常识
本文最后更新于:8 个月前
内容包括:浏览器的渲染过程、url请求全过程、URL介绍、浏览器存储方式、web会话管理…
浏览器常识
一、常见的浏览器内核
浏览器内核,又叫Rendering Engine,可以理解为渲染引擎,用来将代码转换成页面
| 浏览器 | 内核 | 备注 |
|---|---|---|
| IE | Trident | IE、猎豹安全、360极速浏览器、百度浏览器 |
| firefox | Gecko | 现在没落了 |
| Safari | webkit | 从Safari推出之时起,它的渲染引擎就是Webkit,一提到 webkit,首先想到的便是 chrome,可以说,chrome 将 Webkit内核 深入人心,殊不知,Webkit 的鼻祖其实是 Safari。 |
| chrome | Chromium/Blink | 在 Chromium 项目中研发 Blink 渲染引擎(即浏览器核心),内置于 Chrome 浏览器之中。Blink 其实是 Webkit 的分支。大部分国产浏览器最新版都采用Blink内核。二次开发。Edge用的也是Chromium内核 |
| Opera | blink | 现在跟随chrome用blink内核 |
二、渲染过程

根据HTML解析出DOM树(遇到
<img>标签加载图片)解析顺序为:从上到下,深度优先遍历。遇到
link标签时,异步请求资源;遇到script标签,阻塞解析,直到js脚本加载执行完毕(所以script标签通常放在HTML底部,一是不阻塞解析进程、二是防止操作到还没有解析出来的节点导致报错)。CSS文件影响js代码的执行(不影响加载),所以JS代码执行前,必须保证CSS文件已经加载完毕。另外JS只能操作使用link引入的css,无法修改import导入的css根据CSS解析出CSS规则树(遇到背景图片链接不加载)
解析 CSS 规则树时 js 执行将暂停,直至 CSS 规则树就绪
精简CSS可以加快CSS规则树的构建,从而加快页面响应速度
结合DOM树和CSS规则树,生成渲染树(遍历DOM树时加载对应样式规则上的背景图片)
根据渲染树计算每个节点的信息,绘制页面
三、url请求全流程
浏览器输入URL,并回车之后经历的所有过程如下图


- DNS解析域名得到IP地址
- TCP三次握手建立连接
- 客户端向服务端发送请求
- 服务端根据收到的请求端口号、路径,找到对应的资源文件,返回发送给客户端
- 客户端收到返回的资源,解析页面、请求页面中的其它资源
- 客户端渲染页面
- 服务器断开连接(四次挥手)
四、DNS域名解析
DNS 即域名系统,全称是 Domain Name System,域名服务器有以下四种类型
根域名服务器,全球有13个,从
a.rootservers.net命名到m.rootservers.net顶级域名服务器,例如:
com、cn权限域名服务器,负责一个区的域名服务器

本地域名服务器,当一个主机发出DNS查询请求时,这个查询报文就发送给本地域名服务器
域名解析过程
主机向本地域名服务器的查询一般都是采用递归查询,我的理解,即主机把请求发送给本地域名服务器,然后由本地域名服务器代理主机完成所有后续的请求任务,直接返回查询结果给主机
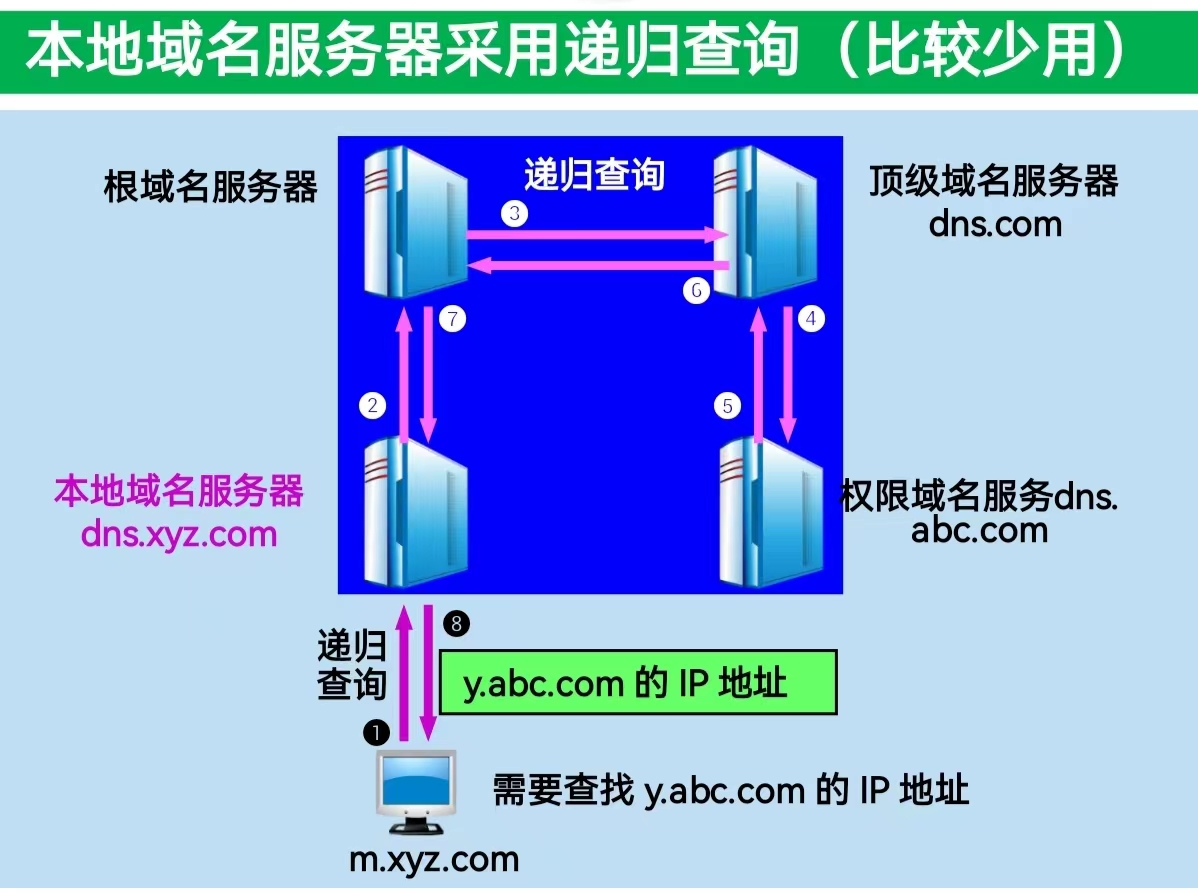
本地域名服务器向根域名服务器的查询通常采用迭代查询。即所有向根域名服务器、顶级域名服务器、或权限域名服务器的请求,都由本地域名服务器进行。

DNS缓存
每个域名服务器都维护了一个高速缓存,存放最近使用过的域名,以及从何处获得名字映射信息的记录。每条记录都设置了一个计时器,保证内容准确。这样可以大大减少对根服务器的访问。
五、端口
为什么需要端口
网络服务器上运行着很多进程,仅仅通过IP地址无法获悉用户请求的是哪个进程的服务。端口就像一个间接层,通过不同的端口号,可以辨别不同的进程。
服务端的进城启动服务时,会绑定对应的web端口,并在对应的端口上持续监听消息,在有请求到来时就去响应。
常用的缺省端口号
| http服务 | 80 |
|---|---|
| https | 443 |
| tomcat | 8080 |
| ssh | 22 |
| mysql | 3306 |
| MongoDB | 27017 |
| ftp | 21 |
六、URL
1、URL与URN、URI的关系
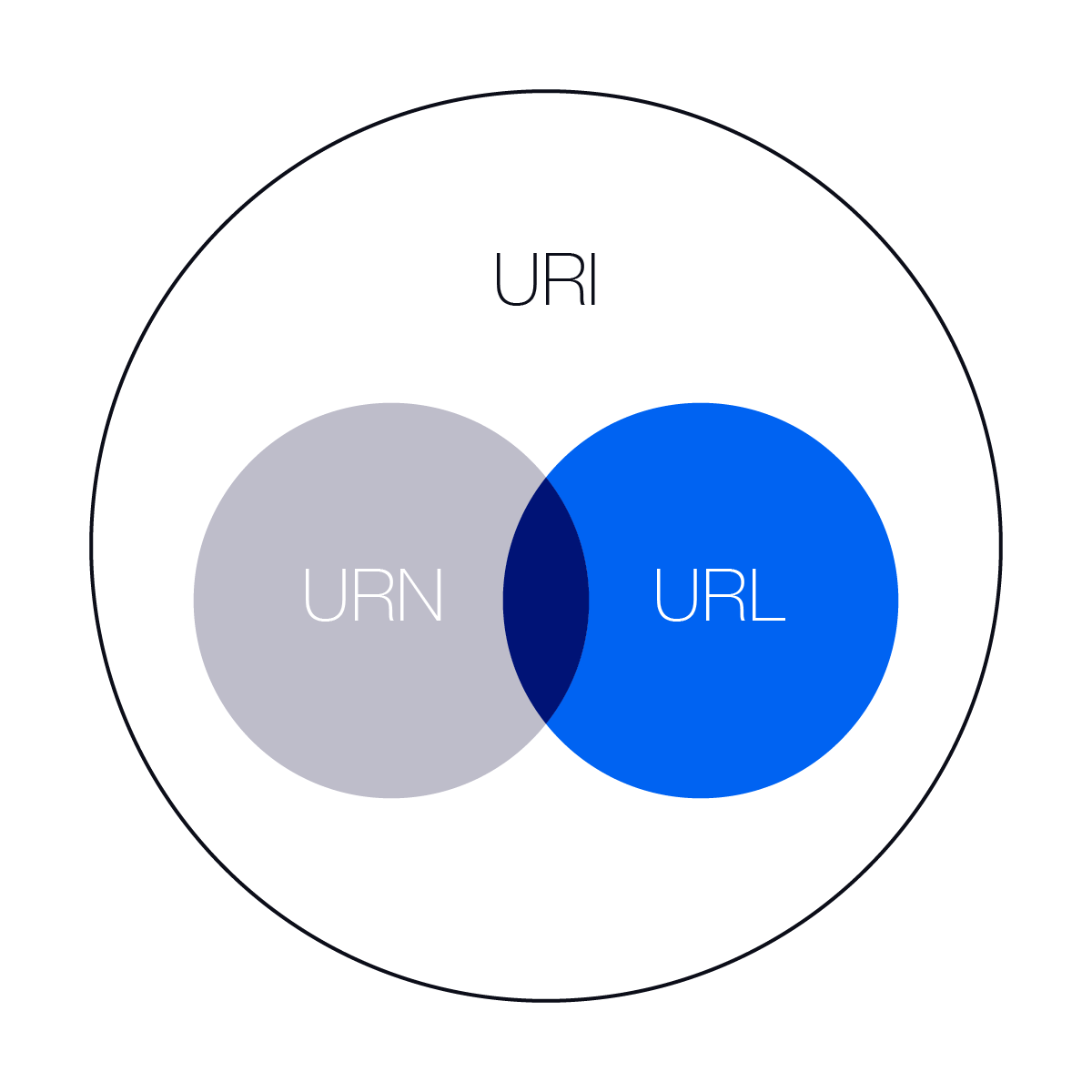
- URL,Uniform Resource Locator,统一资源定位符,我们常说的“网址”
- URI,Uniform Resource Identifier,统一资源标识符
- URN,Uniform Resource Name,统一资源名称,典型例子:
ISBN,图书编号
2、URL结构

- scheme 表示协议名,比如
http,https,file等等。后面必须和://连在一起 - user:passwd@ 表示登录主机时的用户信息,不过很不安全,不推荐使用,也不常用
- host:port表示主机名和端口
- path表示请求路径,标记资源所在位置
- query表示查询参数,为
key=val这种形式,多个键值对之间用&隔开 - fragment表示 URI 所定位的资源内的一个锚点,浏览器可以根据这个锚点跳转到对应的位置
例如:
1 | |
可用字符包括:
URL元字符:分号(
;),逗号(,),斜杠(/),问号(?),冒号(:),at(@),&,等号(=),加号(+),美元符号($),井号(#)语义字符:
a-z,A-Z,0-9,连词号(-),下划线(_),点(.),感叹号(!),波浪线(~),星号(*),单引号('),圆括号(())
除了以上字符,其他字符出现在 URL 之中都必须转义
3、URL转码与解码
encodeURI()
用于转码整个 URL。它的参数是一个字符串,代表整个 URL。它会将元字符和语义字符之外的字符,都进行转义
1 | |
decodeURI()
用于整个 URL 的解码。它是encodeURI()方法的逆运算。它接受一个参数,就是需要解码的 URL
1 | |
另外,还有encodeURIComponent()和decodeURIComponent()两个方法,用于URL片段的转码解码,它会转译除了语义字符之后的所有字符,所以不能用于整个URL,否则会让URL出错
4、URL接口
URL.createObjectURL()
用来为上传/下载的文件、流媒体文件生成一个 URL 字符串。这个字符串代表了File对象或Blob对象的 URL
1 | |
每次使用URL.createObjectURL()方法,都会在内存里面生成一个 URL 实例。如果不再需要该方法生成的 URL 字符串,为了节省内存,可以使用URL.revokeObjectURL()方法释放这个实例
URL.revokeObjectURL()
用来释放URL.createObjectURL()方法生成的 URL 实例。它的参数就是URL.createObjectURL()方法返回的 URL 字符串。
一旦图片加载成功以后,为本地文件生成的 URL 字符串就没用了,于是可以在img.onload回调函数里面,通过URL.revokeObjectURL()方法卸载这个 URL 实例,见上面代码
七、浏览器存储
- localStorage
- sessionStorage
- Index DB
- cookie
cookie的介绍请跳转到:HTTP类目下的《cookie》
1、localStorage
localStorage 属性( IE8 以上的 IE 版本才支持)允许在浏览器中存储 key/value 对的数据,用于长久保存整个网站的数据,保存的数据没有过期时间,直到手动去删除。
localStorage 中的键值对总是以字符串的形式存储
1 | |
一个应用实例:记录按钮的点击次数
1 | |
2、sessionStorage
sessionStorage 属性允许在浏览器中存储 key/value 对的数据,用于临时保存同一窗口(或标签页)的数据,在关闭窗口或标签页之后将会删除这些数据
1 | |
localStorage和sessionStorage除了保存时间不一样外,其它属性和方法都是一致的,它们都继承自Storage接口。有以下1个属性、5个方法
| 属性/方法 | 描述 |
|---|---|
| key(n) | 返回存储中第 n 个键的名称。 |
| length | 返回存储在 Storage 对象中的数据项数。 |
| getItem(keyname) | 返回指定的键名的值。 |
| setItem(keyname, value) | 将键添加到存储中,或者如果键已经存在,则更新该键的值。 |
| removeItem(keyname) | 从存储中删除该键。 |
| clear() | 清空所有键。 |
3、Index DB
浏览器提供的本地数据库,它可以被网页脚本创建和操作。 Index DB 允许储存大量数据,提供查找接口,还能建立索引。 这些都是 localStorage 所不具备的