Hadoop生态圈
本文最后更新于:8 个月前
介绍Hadoop,以及Hadoop主流的生态组件,包括Spark、Flink
通过理清基本概念,建立起对大数据处理技术的基础认知,适合新手入门!
Hadoop生态圈
一、Hadoop是什么?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。Hadoop的框架最初的组成部分、也是最核心的设计就是:HDFS和MapReduce。
Hadoop默认安装是「单机模式」,该模式下无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。读取的是本地数据
「(伪)分布式模式」读取的则是HDFS上的数据。
如何安装使用Hadoop?参见:Hadoop安装教程 - timegogo
二、Hadoop生态圈

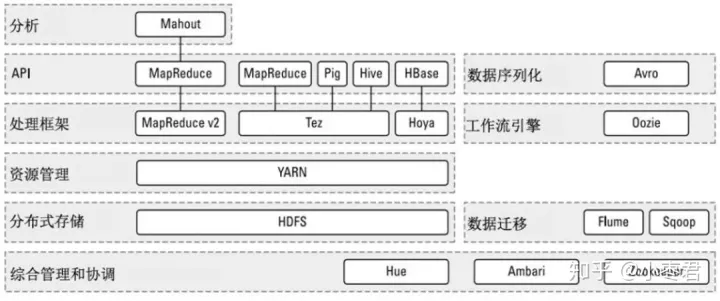
2.1、核心组件
- HDFS,Hadoop Distribution File System,Hadoop分布式文件系统
- MapReduce,分布式计算框架
2.2、重要组件
后续发展起来的一些重要组件
- YARN,资源管理组件,MapReduce2.0的产物
- Spark,内存计算框架,用来提高计算速度。可以理解为是在Hadoop基础上的改进
- Mahout,数据挖掘组件,用于机器学习
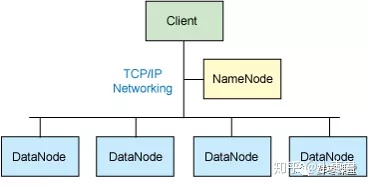
三、HDFS 分布式文件系统
3.1、组成框架
- NameNode,主节点(Master节点),用于管理
- DataNode,从节点(Slave节点),用于储存,是文件储存的基本单位
- Client,用来与NameNode交互,访问HDFS
3.2、HDFS常用命令
bin/hdfs dfs命令 - starzy - 博客园 (cnblogs.com)
四、Spark 内存计算框架
4.1、Scala
基于Java的一门编程语言,集成了面向对象编程和函数式编程,比Java简洁和强大、是Spark使用的主流语言。
更多细节请看:Scala——Spark框架使用的主流语言 - timegogo
4.2、Spark是什么
Apache Spark™ is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters.
——Spark官方
Apache Spark™ 是一个多语言引擎,用于在单节点机器或集群上执行数据工程、数据科学和机器学习。
它提供了Java、Scala、Python和R的高级API,以及支持通用执行图的优化引擎。
4.3、Spark工具
- Spark Core,实现了 Spark 的基本功能,包含RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块
- Spark SQL,Spark 用来操作结构化数据的程序包。通过它可以使用SQL操作数据
- Spark Streaming,Spark 提供的对实时数据进行流式计算的组件
- Spark MLLib,机器学习库
- Spark GraphX,Spark中用于图计算的API
4.4、Spark的特点
- 快,基于内存
- 易用,提供Scala、Java、Python、R四种语言的API
- 兼容,?
4.5、如何使用Spark
五、Flink
参考文章
[1].深入浅出大数据:到底什么是Hadoop? - 知乎 (zhihu.com)
Hadoop生态圈
http://timegogo.top/2022/12/01/大数据/Hadoop生态圈/