Hadoop安装教程
本文最后更新于:8 个月前
介绍在CentOS7(虚拟机)下,安装Hadoop2.10.2的流程
介绍Hadoop单机配置和伪分布式配置
以及Yarn的使用
Hadoop安装教程
一、前置条件
- VMWare虚拟机上安装CentOS7
- CentOS7上安装Java11 OpenJDK
- CentOS7上安装ssh
1.1、Hadoop与Java的版本关系

- Hadoop3.3以上,支持Java8和Java11
- Hadoop3.0到3.2,只支持Java8
- Hadoop2.7到2.10,支持Java7和Java8
同时,建议使用OpenJDK

官方链接:Hadoop Java Versions - Hadoop - Apache Software Foundation
1.2、安装Java环境
1.3、安装ssh,设置免密码登陆
CentOS7,已经内置了ssh。所以不需要另外安装
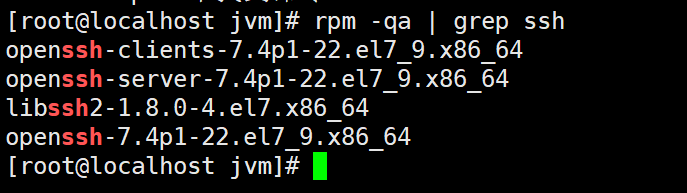
测试ssh是否可用
1 | |
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 (CentOS7用户的密码),这样就登陆到本机了。
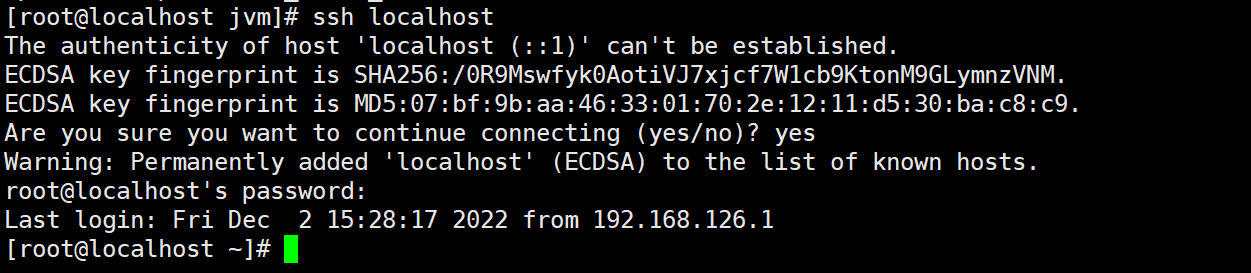
配置ssh免密码登陆
1 | |
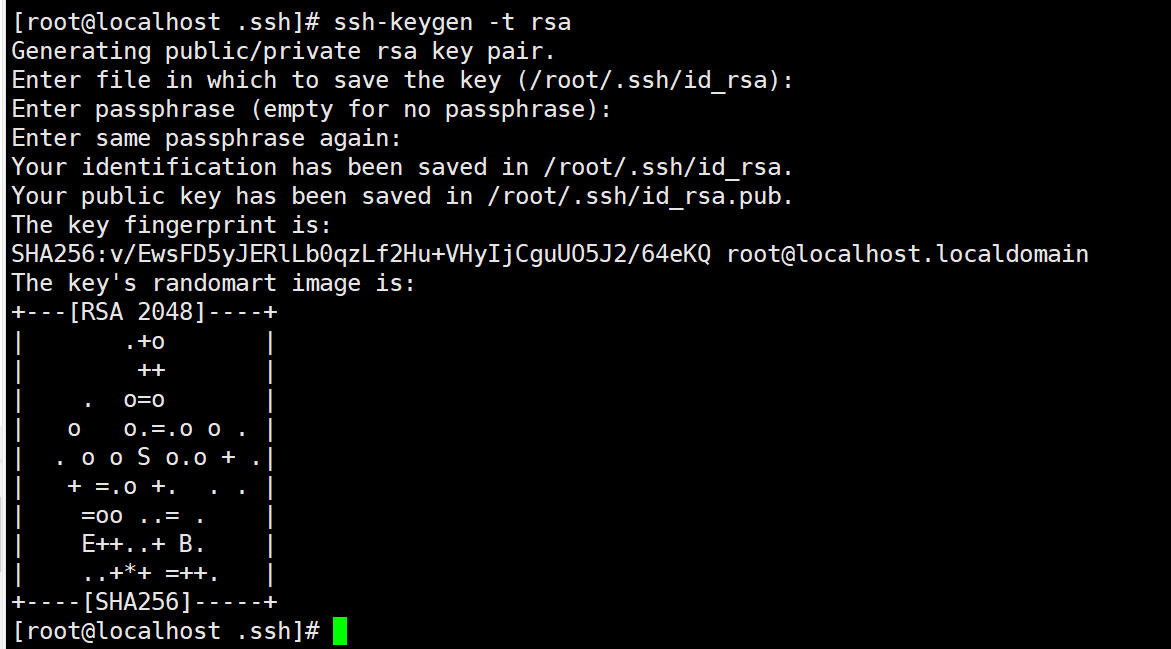
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了
二、安装Hadoop
Hadoop下载链接:http://mirrors.cnnic.cn/apache/hadoop/common/
这里我选择下载2.10.2版本。对应的是Java8。要下载.tar.gz文件,这是编译好的,另一个包含 src 的则是 Hadoop 源代码,需要进行编译才可使用。
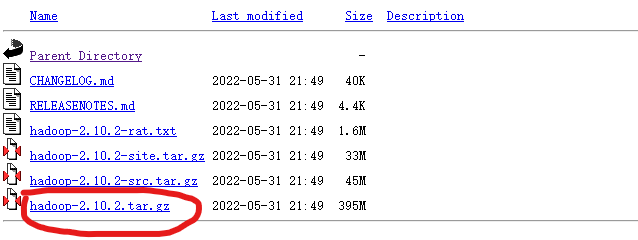
我从浏览器下载到了Windows10中,需要借助XFtp传输到虚拟机上
接下来,将Hadoop安装到/usr/local/目录下
1 | |

三、Hadoop单机配置(非分布式)
Hadoop 默认模式为非分布式模式,无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
现在我们可以执行例子来感受下 Hadoop 的运行。Hadoop 附带了丰富的例子(运行 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar 可以看到所有例子),包括 wordcount、terasort、join、grep 等。
在此我们选择运行 grep 例子,我们将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中。
1 | |
作业的结果会输出在指定的 output 文件夹中,通过命令 cat ./output/* 查看结果,符合正则的单词 dfsadmin 出现了1次:
注意,Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先将 ./output 删除。
1 | |
四、Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
在设置 Hadoop 伪分布式配置前,我们还需要设置 HADOOP 环境变量,执行如下命令在 ~/.bashrc 中设置:
1 | |
这些变量在启动 Hadoop 进程时需要用到,不设置的话可能会报错。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
修改core-site.xml,将
1 | |
修改为:
1 | |
修改hdfs-site.xml,将
1 | |
修改为:
1 | |
关于Hadoop配置项的一点说明: 虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
配置完成后,执行 NameNode 的格式化:
1 | |
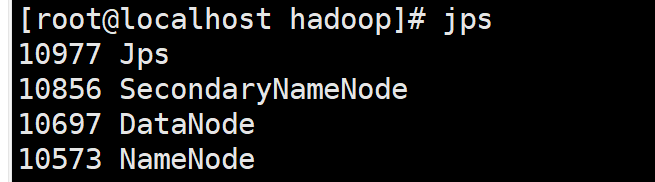
接着开启NameNode和DataNode守护进程
1 | |
若出现如下 SSH 的提示 “Are you sure you want to continue connecting”,输入 yes 即可。
1 | |
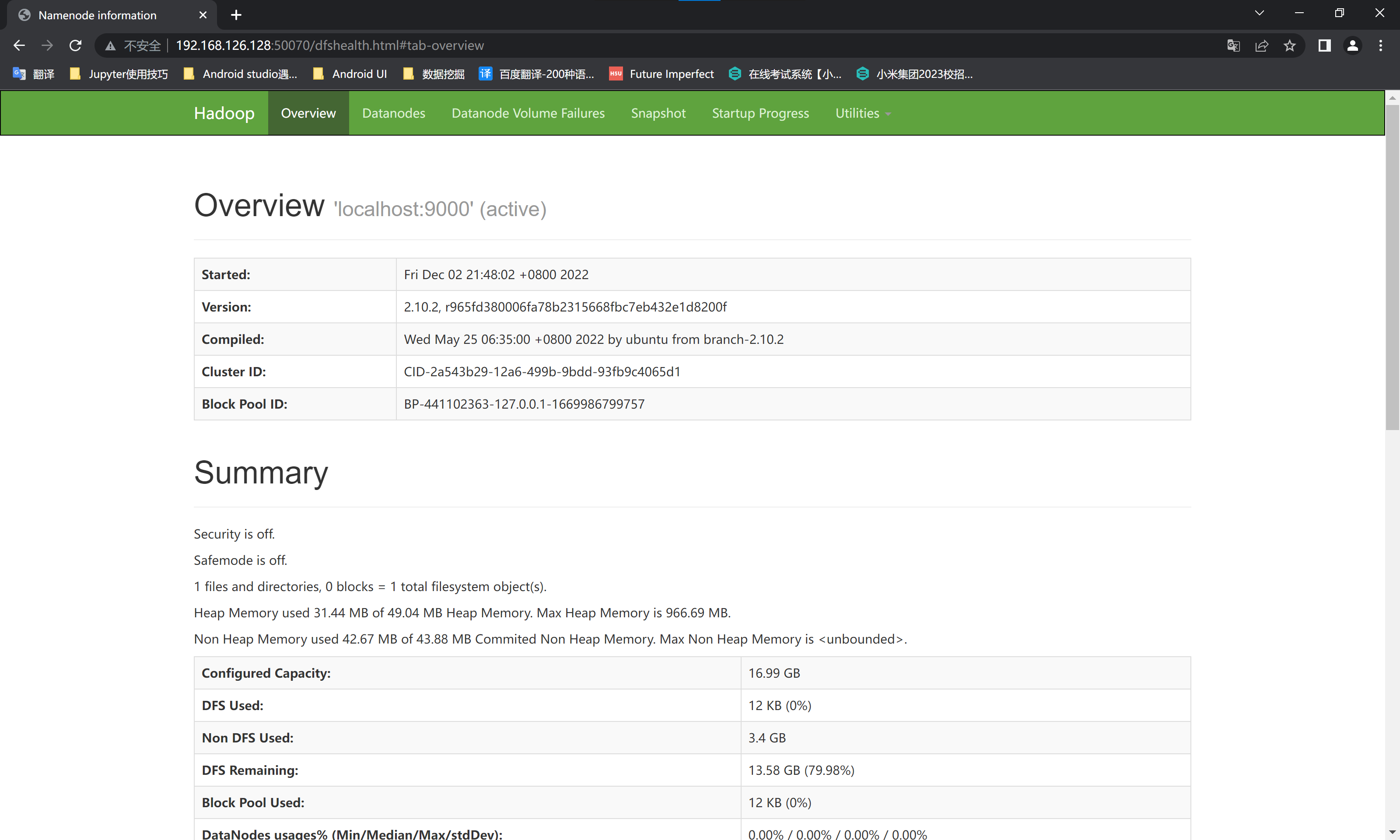
成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
由于我们的hadoop安装在虚拟机的CentOS7主机上,而且没有安装GUI。所以需要通过宿主机的浏览器查看。直接输入CentOS7的ip+端口无法访问。需要解决一下这个问题:宿主机访问VMWare虚拟机端口服务 - timegogo
五、运行Hadoop伪分布式实例
直接阅读原文:Hadoop安装教程_伪分布式配置_CentOS6.4/Hadoop2.6.0_厦大数据库实验室博客 (xmu.edu.cn)
六、启动YARN
直接阅读原文:Hadoop安装教程_伪分布式配置_CentOS6.4/Hadoop2.6.0_厦大数据库实验室博客 (xmu.edu.cn)


七、启动、关闭命令
1 | |
我们在主文件夹 ~ 中执行 ls 这个命令时,实际执行的是 /bin/ls 这个程序,而不是 ~/ls 这个程序。系统是根据 PATH 这个环境变量中包含的目录位置,逐一进行查找,直至在这些目录位置下找到匹配的程序(若没有匹配的则提示该命令不存在)。
上面的教程中,我们都是先进入到 /usr/local/hadoop 目录中,再执行 ./sbin/hadoop,实际上等同于运行 /usr/local/hadoop/sbin/hadoop。我们可以将 Hadoop 命令的相关目录加入到 PATH 环境变量中,这样就可以直接通过 start-dfs.sh 开启 Hadoop,也可以直接通过 hdfs 访问 HDFS 的内容,方便平时的操作。
在前面我们设置 HADOOP 环境变量时,我们已经顺便设置了 PATH 变量(即 “export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin”),那么以后我们在任意目录中都可以直接通过执行 start-dfs.sh 来启动 Hadoop 或者执行 hdfs dfs -ls input 查看 HDFS 文件了,读者不妨现在就执行 hdfs dfs -ls input 试试看。
参考文章
[1].Hadoop安装教程_伪分布式配置_CentOS6.4/Hadoop2.6.0_厦大数据库实验室博客 (xmu.edu.cn)
[2].Apache Hadoop 3.3.4 – Hadoop: Setting up a Single Node Cluster.