Spark从搭建到运行
本文最后更新于:8 个月前
记录在CentOS7虚拟机下,搭建Spark运行环境、安装Spark的过程。
以及介绍如何使用Spark Shell运行代码,如何编写Spark程序、并提交到Spark上运行
Spark从搭建到运行
一、Spark运行环境
- CentOS7(虚拟机),VMWare安装CentOS7 - timegogo
- Java JDK 1.8.0,Linux安装Java环境 - timegogo
- Hadoop 2.10.2,Hadoop安装教程 - timegogo
- Spark 2.1.0
二、安装Spark
在宿主机(Windows10)下,访问http://spark.apache.org/downloads.html,下载
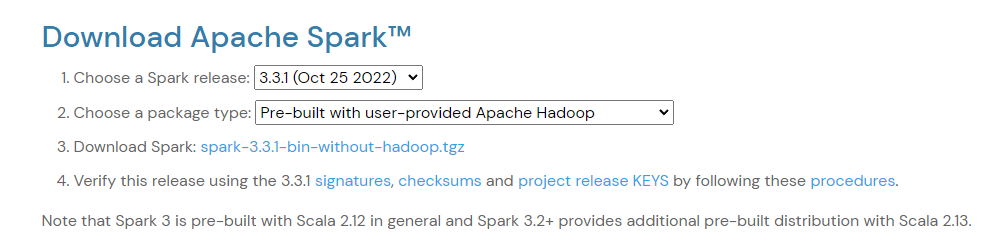
(Apache官网下载速度极慢,这里使用清华大学镜像源代替Index of /apache/spark/spark-3.3.1 (tsinghua.edu.cn))

由于我们已经自己安装了Hadoop,所以选择下载*-without-hadoop.tgz包,它属于“Hadoop free”版,这样,下载到的Spark,可应用到任意Hadoop 版本。
Spark部署模式主要有四种:Local模式(单机模式)、Standalone模式(使用Spark自带的简单集群管理器)、YARN模式(使用YARN作为集群管理器)和Mesos模式(使用Mesos作为集群管理器)。
这里介绍Local模式(单机模式)的 Spark安装。
首先通过XFtp,将tgz包传输到虚拟机上。然后进行安装:
1 | |
安装后,还需要修改Spark的配置文件spark-env.sh
1 | |
有了上面的配置信息以后,Spark就可以把数据存储到Hadoop分布式文件系统HDFS中,也可以从HDFS中读取数据。如果没有配置上面信息,Spark就只能读写本地数据,无法读写HDFS数据。
配置完成后就可以直接使用,不需要像Hadoop运行启动命令。
1 | |

三、用Sprak Shell运行代码
学习Spark程序开发,建议首先通过spark-shell交互式学习,加深Spark程序开发的理解
Spark shell 提供了简单的方式来学习 API,并且提供了交互的方式来分析数据。你可以输入一条语句,Spark shell会立即执行语句并返回结果,这就是我们所说的REPL(Read-Eval-Print Loop,交互式解释器),为我们提供了交互式执行环境,表达式计算完成就会输出结果,而不必等到整个程序运行完毕,因此可即时查看中间结果,并对程序进行修改,这样可以在很大程度上提升开发效率。
Spark Shell 支持 Scala 和 Python,这里使用 Scala 来进行介绍。
前面已经安装了Hadoop和Spark,如果Spark不使用HDFS和YARN,那么就不用启动Hadoop也可以正常使用Spark。如果在使用Spark的过程中需要用到 HDFS,就要首先启动 Hadoop(启动命令见:Hadoop安装教程 - timegogo)
这里假设不需要用到HDFS,因此,就没有启动Hadoop。现在我们直接开始使用Spark。
3.1、spark-shell命令
spark-shell命令及其常用的参数如下:
1 | |
<master-url>的可选项如下:
- local 使用一个Worker线程本地化运行SPARK(完全不并行)
- local[*] 使用逻辑CPU个数数量的线程来本地化运行Spark
- local[K] 使用K个Worker线程本地化运行Spark(理想情况下,K应该根据运行机器的CPU核数设定)
- spark://HOST:PORT 连接到指定的Spark standalone master。默认端口是7077.
- yarn-client 以客户端模式连接YARN集群。集群的位置可以在HADOOP_CONF_DIR 环境变量中找到
- yarn-cluster 以集群模式连接YARN集群
下面启动spark-shell环境
1 | |
该命令省略了参数,这时,系统默认是“bin/spark-shell –master local[*]”
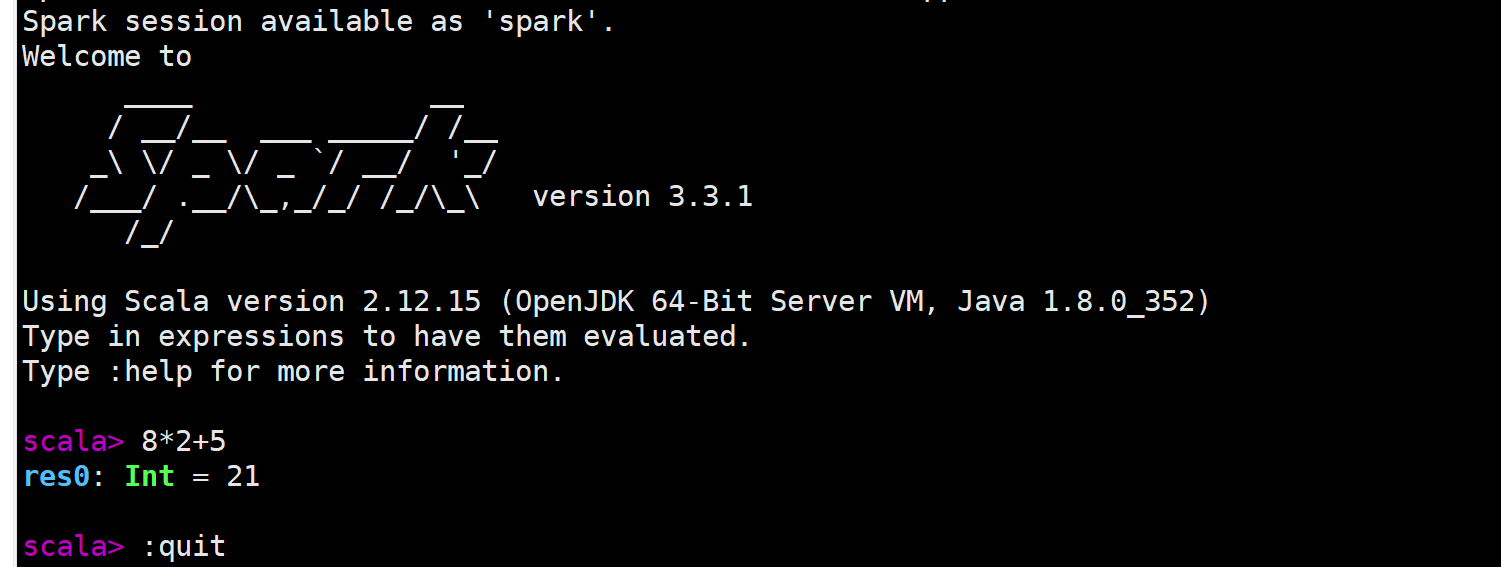
1 | |
四、编写Spark程序
下面通过一个简单的应用程序 SimpleApp 来演示如何通过 Spark API 编写一个独立应用程序。使用 Scala 编写的程序需要使用 sbt 进行编译打包,相应的,Java 程序使用 Maven 编译打包,而 Python 程序通过 spark-submit 直接提交。
4.1、安装sbt
sbt(Simple Build Tool)是对Scala或Java语言进行编译的一个工具,类似于Maven或Ant,需要JDK1.8或更高版本的支持,并且可以在Windows和Linux两种环境下安装使用。
参照sbt - Download (scala-sbt.org)中的指引进行安装
按照指引安装好后,输入命令查看sbt版本信息
1 | |

4.2、编写Scala程序
创建一个文件夹 sparkapp 作为应用程序根目录
1 | |
在 ./sparkapp/src/main/scala 下建立一个名为 SimpleApp.scala 的文件
1 | |
这种编写方式,只适合编写简单的程序,如果需要编写更复杂的逻辑,就需要使用到IDEA。
这里一并介绍IDEA如何进行远程开发,IDEA远程开发 - timegogo
4.3、使用sbt打包程序
请在./sparkapp 中新建文件 simple.sbt
1 | |
接着,我们就可以通过如下代码将整个应用程序打包成 JAR(首次运行同样需要下载依赖包 ):
1 | |
对于刚安装好的Spark和sbt而言,第一次运行上面的打包命令时,会需要几分钟的运行时间,因为系统会自动从网络上下载各种文件。后面再次运行上面命令,就会很快,因为不再需要下载相关文件。
打包完成后会输出如下信息

生成的 jar 包的位置为 ~/sparkapp/target/scala-2.12/simple-project_2.12-1.0.jar
4.4、通过spark-submit运行程序
最后,我们就可以将生成的 jar 包通过 spark-submit 提交到 Spark 中运行了,命令如下
1 | |

五、使用IDEA+SBT编写Spark程序
5.1、搭建IDEA远程开发
由于虚拟机上的CentOS7没有GUI,所以无法使用IDEA。解决办法是在宿主机Windows10的IDEA上使用IDEA的远程开发服务。
IDEA会在Windows10本地安装一个JetBrain GateWay。在CentOS7(远程服务器)上安装一个IDEA Backend。
打开远程界面如下:
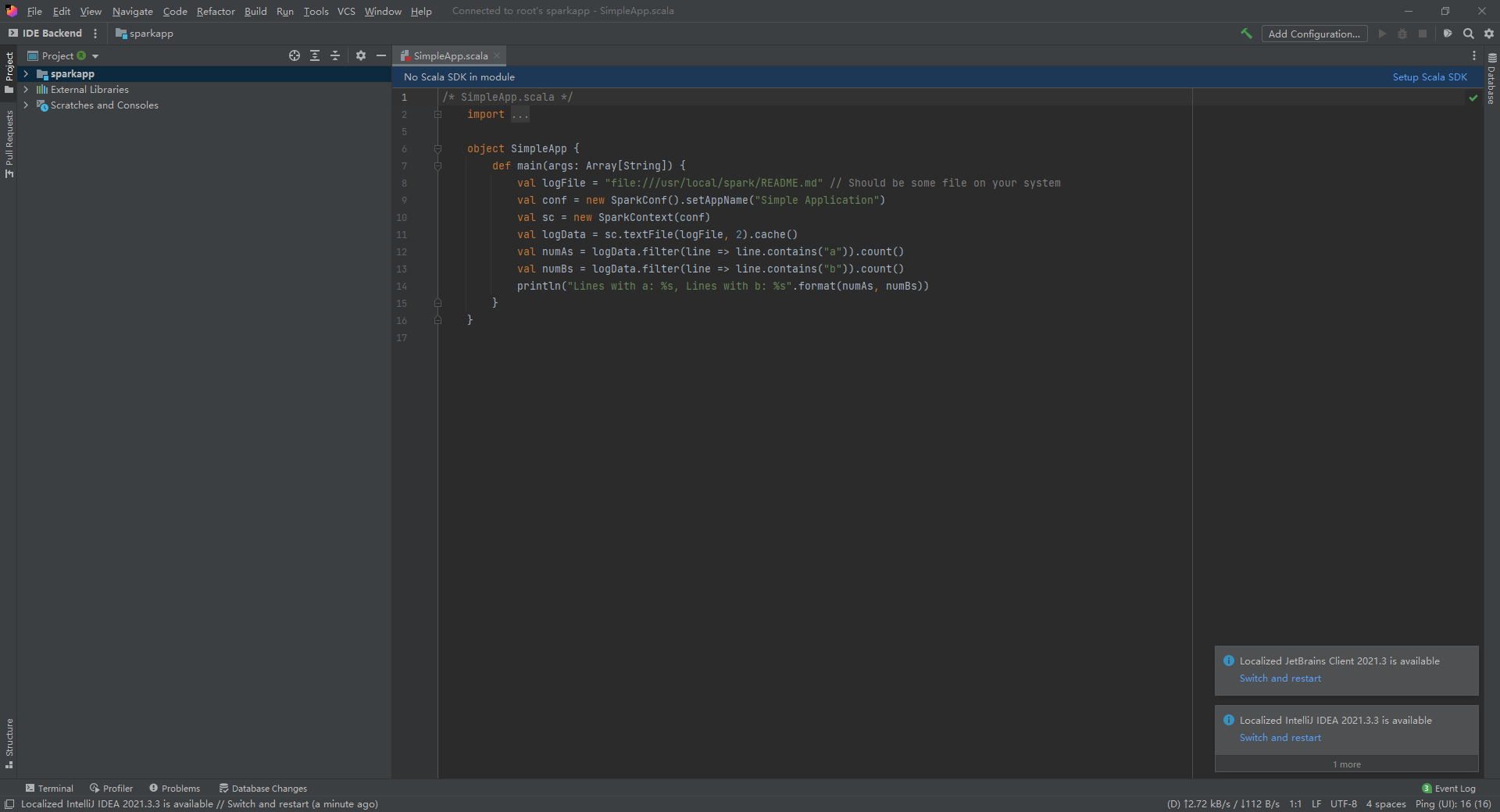
同时,还需要在CentOS7的IDEA服务端上安装Scala插件,安装Scala SDK。
具体搭建过程见这篇:IDEA远程开发 - timegogo
5.2、安装Scala SDK
直接使用IDEA提示安装Scala SDK速度极慢(访问国外服务器的原因,速度只有几kb、几十kb)。所以我们先在[镜像网站](Index of /scala2.12 (macports.org))上下载好Scala SDK,然后在CentOS 7上手动安装。
我在Windows10的浏览器中下载,需要XFtp传输到CentOS7虚拟机上(也可以在Linux中通过wget或curl命令直接下载.tgz文件)
然后,进行解压,
1 | |
添加环境变量,(无论是哪种内核(版本)的系统,都可以通过修改profile或者bashrc的配置信息来达到设置环境变量的目的)
1 | |

在CentOS7安装好Scala后,打开IDEA时,会自动提示你安装Scala SDK,并提供系统上的Scala供你选择
5.3、创建项目
由于IDEA不支持远程新建项目,所以只能”曲线救国“。在Windows下新建出项目,但是依赖的版本按照远程CentOS7的来配置。本地创建出项目后,再用XFtp传输到远程CentOS7上。
吐槽一波,这样的操作实在是太麻烦了。对于Spark开发来说,运行环境在服务器上,但是现在哪有工业服务器带GUI的。所以也就不可能直接在服务器上使用IDE创建项目。但是如果本地创建项目,需要运行测试的时候又没有运行环境。所以就很麻烦!
这里还需要解决一下【项目根目录】的问题,见:IDEA远程开发 - timegogo-设置项目根目录
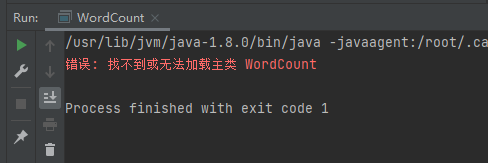
经过一系列”曲线操作“,发现还是无法正常使用(心态崩了)。如下图,BackEnd上没有Scala Class的选项。

即使通过File类型去添加.scala后缀也不管用
因此决定还是安装GUI,在CentOS7上安装IDEA。参考:CentOS7安装GUI界面及远程连接的实现 - 腾讯云开发者社区-腾讯云 (tencent.com)
参考链接
[1].Spark2.1.0入门:Spark的安装和使用_厦大数据库实验室博客 (xmu.edu.cn)
[2].http://spark.apache.org/downloads.html
[3].Index of /apache/spark/spark-3.3.1 (tsinghua.edu.cn))