LAF项目总结
本文最后更新于:8 个月前
总结失物招领网站项目
一、项目结构
前端项目结构
1 | |
以上的文件都是在开发过程中,陆续新建的,在开发过程中,根据实际需要修改优化过结构。目前项目2.0版本已经完成,现在来看文件的划分,仍存在一些可以优化的地方:
- /utils目录下,token.js 和 localStorage.js 其实可以合并为一个文件,因为它们都是涉及到 localStorage 的操作
后端项目结构
1 | |
二、使用的npm包
前端部分:
1 | |
后端部分:
1 | |
三、项目功能
- 浏览、发布失物/寻物信息。信息内容包括:
- 文字:物品信息、用户信息
- 图片:一组展示物品的图片
- 时间:物品丢失的大致时间、信息发布的时间
- 地点:物品丢失的地点、物品现存放的地点
- 搜索信息,提供以下搜索方式:
- 输入关键字
- 按时间,”当天“、”3天内“、”一周内“、指定起始-终止日期
- 按校区
- 按物品分类
- 以上3种(时间、地点、物品分类)的组合
- 举报违规信息
- 管理个人的身份信息,管理的信息包括:昵称、学院、邮箱、联系电话
- 退出登陆与切换账号
- 修改密码
- 管理个人的信息记录,包括:
- 用户自己发布的失物、寻物信息,操作包括:
- 查看
- 标记“已找回”
- 修改编辑
- 删除
- 收藏标记的帖子,操作包括:
- 查看
- 取消收藏
- 用户自己发布的失物、寻物信息,操作包括:
四、项目亮点
响应设计,支持跨端浏览
五、项目难点
系统设计,很难一次性就设计合理,需要不断迭代优化
数据集合和数据字段的设计很难一次就合理,经历了不断迭代完善
在做系统设计的时候,对数据字段的设计没有深入的考虑到实际情况,导致一些字段的设计不合理。最典型的一个例子:一个帖子分类字段,值修改了三次,连带数据库修改了三次。
因为项目叫做 ”LostAndFound“(失物寻回的意思),所以想当然的将帖子的分类也分成了
lost和found,但是直到后面做前端的时候才发现,用这两个名词去区分 失物招领 和 寻物启事 完全不合理,因为语义不明显。于是,将帖子的分类改成了 “失主寻失物”和“失物寻失主”;对数据库的数据一顿修改。又过了一段时间,又感觉用这两段中文去描述两种分类还是不理想,描述还是不够明显。于是,又将数据库里面的所有分类字段修改了一次,改成
loser_post和picker_post,这次终于达到能够明显区分的状态了。功能逻辑本身虽然简单,但是边需要考虑的边界情况不少,很难一次性考虑全面
前端逻辑的处理细节也很难一次考虑全面,经常是需要不断地测试、修改
举几个例子:(1)加载用户信息的时机判断,一开始是进入个人页并发现pinia中没有用户数据时,才加载用户信息。但是这里面隐藏了一个bug,当用户切换账号之后,pinia中却还保留着上一个用户的数据。发现这个bug之后,对用户数据的加载逻辑进行了修改,改成只要一进入个人页就重新加载用户信息,改完之后逻辑才对。
第一代加载方案,以及存在的问题
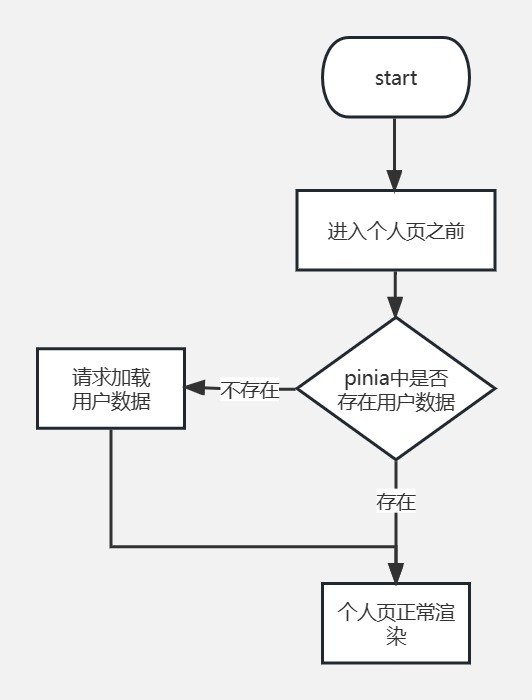
.png)
为了解决这个bug,推出了 第二代加载方案
.png)
实际上,只需要在用户登陆之后执行一次用户数据的加载,再加上pinia持久化储存,就足够了!
(2)pinia 刚开始并没有采用持久化储存,导致出现了一个bug:如果不是在个人页触发网页刷新,就会使pinia中的用户数据丢失,如果这时再进行发布操作的话,其中绑定记录到用户数据的操作,会因为访问空对象而报错。发现问题后才采取了 pinia 持久化储存的方案 解决了这个bug
越到后面越感觉,需求分析也是一件很难的事情,产生这样感觉的背景是:随着时间的推移,总会感觉有些功能和逻辑上的设计不够合理,不能很好地符合实际需求,所以就会产生推倒一些设计重构的想法。但是实践这些想法,进行重构的工作量完全不小。
涉及到技术比较多,覆盖前后端
涉及到技术包括:服务器操作、数据库配置、web服务器(Nginx)配置、后端开发、前端开发
服务器涉及:Linux系统的操作
数据库涉及:MongoDB数据库的安装、身份验证配置
web服务器配置涉及:Nginx的安装、https二级域名的配置、反向代理的配置
后端开发涉及:mongoose库的使用、CORS跨域资源请求配置、JSONWebToken的使用、数据单向加密、路由权限验证、所有前端功能请求逻辑的设计与实现
前端开发涉及:响应式页面搭建、路由配置、路由权限管理、全局状态管理、等所有功能需求的实现
五、项目技术点
- 自动化部署
- 响应式设计
- 媒体查询
- grid布局多列自动填充
- 使用ant-design栅格系统
- 路由权限控制
- 登陆跳转
- 修改个人信息时动态检测内容是否发生更改并反馈
- 密码加密保存
- 跨域配置
- 日志打印
六、体会收获
不要在主题样式上花过多时间。
在编码开始之前,特意花了时间去做了一下主题样式的设计,初衷是希望做出点自己的特色。但,毕竟不是专业的,事倍功半,一开始定义的很多全局css变量,颜色、大小等等,最后其实并没有用上。可能是没有经验的缘故,所以规划做的并不是很实用,很多事先的规划事后都因为发现不够实用而推倒了。
实际上,ant-design已经提供了成熟的主题方案,后面几乎都是套用了ant-design现成的方案,事实证明,这样节省了很多时间。
避免重复造轮子,要有效地利用现成的东西。
编码初始,写登陆页时,没有使用ant-design,样式和逻辑都是自己写的,代码量还是很大的,更关键的是,很多细节的处理自己做的并不成熟。所以后来几乎所有组件都使用了ant-design,包括最后登陆页,也用ant-design重构了。
一开始全部都自己写的初衷是:尽可能地锻炼自己的开发能力。但是发现,光练不行,得先学,学习优秀的案例、ant-design就是这样一个优秀的案例,项目结束后,可以去研究ant-design组件的源码,学习它的思路逻辑。
对于大多数技术都是:边学边用、边用边学
写样式的时候,发现写了很多重复的选择器,原因是css不支持嵌套。后面就犹豫要不要用scss,但是又没有用过scss。最后,还是决定花一点时间学习一个scss嵌套的使用,需要用什么就先学什么。
如果按照过去的思路,可能会先把scss的所有用法都先学一遍,然后再去用它。
现在发现,其实并不用那样,甚至那样是不合理的。如果都是按照那样的学习思路的话,掌握新技能的速度就会大打折扣,因为要花上很多时间学一时用不到的东西,然后下次要用的时候又忘了,这就是它不合理之处。
全栈开发,最好的开发步骤是:分模块前后端一起完成
而不是先做完后端再做前端,也不是先写完前端再写后端。该项目前后端均由我一个人实现,我的实现顺序是先写完后端再写前端,但是在前端开发过程中,发现了许多原先设计并不合理的地方,比如一些数据字段设计不合理,比如方法设计不合理等等。这时候,不仅要写前端,还需要把已经写好的后端进行重写,于是之前的工作就失去价值了,时间也浪费了。
如果先写前端的话,那么就没有数据来源,也无法实现交互。当然你会说可以用mock这种去模拟数据。但是我既然都要实现后端的,为什么还要多一个步骤,去写一个mock呢?那个是前后端分离开发才用的东西。
大量的时间其实花在了迭代优化上。
在开发之前,对数据库和数据集合进行了设计,(1)很多内容其实是没有必要的,但是一开始没有想到,比如用户的个人信息,一开始设置了很多字段:姓名、学号、学院、年级、头像、电话、邮箱等等,但是在前端写到个人页面时,发现其实姓名、年级对于这个网站其实是可有可无的数据,即使存在也发挥不了什么作用,头像其实也是可有可无的东西。所以在开发过程中,又对数据字段进行了优化重构。(2)一些数据字段、数据集合的命名很不合理,比如一开始将帖子的类型采用了
lost和found这两个名词,但是后面发现,这两个名词很难进行区分,即使是自己设计的都很容易混淆,所以开发过程中又抽出时间把集合名修改了,导致数据又要重新生成。(3)数据集合的划分一开始不合理,甚至自相矛盾了。用户信息集合里有一个字段,是一个数组,保存用户发布过的帖子记录的外键,但是帖子却根据类型分成了两个,这就导致获取用户信息时无法直接通过外键进行表连接,这就属于是设计不合理带来逻辑处理上的麻烦要解决这个问题,一方面要靠经验的积累。另一方面,就如上一点所说的,分模块进行开发,这样能够使修改的范围尽可能小,减小工作量。
严格统一的规范能够带来开发效率低显著提升
规范包括很多方面:各种命名规范、请求头字段的规范、响应内容的规范。
比如响应内容的规范,所有的规范都严格遵守一个格式,前端处理起请求结果时,就能够从容不迫,因为所有的返回内容的结构都是一样的,处理起来的步骤也是相同的,这样省事很多。如果返回内容的格式不一致,有些错误是通过
{success:false}的方式来返回,有些错误是通过错误状态码(如:status:500)来返回的话,前端处理的时候就需要一个一个特别仔细地去查看,这是很费精力和时间的。比如css类名命名的规范,如果有些css类名用短横线
home-view-container,而有些css类名用下划线home_view_wrapper,另外一些类名又用其它方式的话,引用类名的时候不仅需要特别留心地去查看每一个类名,还特别容易混淆和出错,甚至出错了都很难发现,因为它们之间看起来差别不大。另外,css类名一定不能太简单,要有区分度,否则可能会意外地命中其它标签要培养组件化开发的思维
组件化开发,是指将重复的代码和逻辑抽离成一个单独的文件,称之为组件。这样至少有3个好处:(1)减少冗余的代码,重复的代码都提取到一个文件中了,要用它的地方只需要引入这个文件就可以了,不用重复写一遍基本相同的代码。(2)方便维护,对该部分修改的时候,只需要修改组件文件就可以了;如果不是组件化的话,需要在每个用到它的地方去修改一遍,不仅工作量大而且容易遗漏。(3)将一个复杂的模块从原文件拆分出去,还可以减少原文件的代码行数,能够减小原文件的阅读和维护难度。
尽管有些时候因为组件件通信的需要,抽离组件不是那么容易,但是其实认真一点就会发现其实也没有那么难,可能只是你不熟而已。
任务规划可以有效提升开发速度
我个人在开发时会比较纠结,常常会在细节上花费大量的时间去思考如何优化,从而拖慢了项目的进度;而且有时候做着做着自己就会迷失方向,不知道下一步该做什么了。所以后来自己开始做项目规划,每天开始编码前,将所要完成的任务内容尽可能细化地写下来,遇到需要优化的细节时,写在任务规划中,而不是立即执行,然后对照着任务规划,完成一项记录一下再接着进行下一项。